作者:Paul Sztorc
欺诈证明(Fraud Proof)是个极为复杂且烦人的概念,但如果你想知道我的一些心得,请耐着性子跟我一起思考吧。

- Benihime Morgan 的河流艺术作品 -
简而言之,言而简之
- SPV 节点非常易于运行及扩展;借助欺诈证明,SPV (Simplified Payment Verification,简易支付验证)节点可以具备和全节点相同的安全性。
- 我要在此引入 “ SPV+ ” 模式;常规的 SPV 节点只需要保存区块头(存储增量每年约 4MB ),而 SPV+ 节点还需要保存每个区块中的第一笔及最后一笔交易(存储增量每年约 115 MB)。
- “SPV+” 节点必须与一个全节点建立支付通道,或是建立一个 LN(闪电网络)连接。
- 每验证一个区块的正确性,SPV+ 节点都必须向这些全节点支付小额费用;我估计这笔费用不会超过 50 美元/月。
- 后续就是添加几个新操作码的事:我们需要一个【链下的】范围证明(rangeproof),搭配类似 “ SegWit” 的 witness-commitment (见证-承诺)技术,就能方便且低成本地使用 SPV+ 节点了。
1. 背景
A. 如何让比特币更像实体黄金
比特币在设计上对标的是黄金;虽然在很多方面,比特币已远胜于黄金,但是一谈到收款,问题就来了 —— 你怎么知道钱到账了?如果以黄金等实物手段支付,有没有到帐是很简单的 —— 就跟所有一手交钱一手交货的情形一样;但如果使用比特币(数字货币)支付,保障资产所有权就会变成一件很抽象的事。
对于这个问题,中本聪(Satoshi)提出了一个完美的软件解决方案,让你能够知道钱到账没有 —— 它就是 “比特币” 软件。
等会!这不又兜回原点了吗?究竟这个软件是如何运作的?
比特币软件使用一种特殊的机制与其它运行软件的计算机进行同步;这个机制有点类似 Dropbox ,但不同之处在于,它断言了自身的同步状态,因此不会有版本控制的问题。换言之,“得知钱已到账” 和 “得知你已实现同步”是一码事。
中本聪在白皮书中提出了两种 “确认钱已到账” 的方法:
- 【正向做法(传统)】运行软件,等待实现完全同步。
- 【反向做法(实验性)】首先,运行一个 “轻客户端”——只会策略性地对某些简单部分进行同步;然后注意是否出现 “alert(警告)”。
第一种方法就是所谓的 “全节点”,依靠的是 positive proof(正向证明)—— 你理应看到 X,一旦你看到 X ,就知道自己已经收到钱了;第二种方法称为“ SPV 模式” 1,依靠的是 negative proof(反向证明)—— 你本不应看到 Y,一旦你看到 Y,就知道自己没有收到钱。这里的 Y 就是白皮书中提到的 “alert(警示)”,现在大家可能更常听到另一种叫法 —— “欺诈证明(fraud proof)”。
B. “alert” 的理论支撑
我个人觉得最有意思的,反向证明机制(即, “alert”)与实际生活中的很多行为方式类似。
试想以下例子:
- 我们不会试图 100% 杜绝凶案发生,而是在凶案发生后尽全力抓捕犯人(通过庭审定罪,给予犯人应得的惩罚)。
- 我们不会试图 100% 杜绝奸商存在,但如果真的出现奸商,我们会期待他被市场淘汰,然后由良商取而代之;如果有太多利益纠葛,我们会通过侵权法或规章制度淘汰我们不想要的行为。
- 我们不会试图保证每一项发布的科研成果是 100% 零错误的,而是最大程度地公开它们,并期待能收到批评或指正。
- 我们不会试图 100% 防止司法腐败。但是我们确实要求所有法律诉讼环节都必须记录下来,保证庭审的公正性可由公众及法律学者在事后追查。
- 我们不会试图变得 “全知全能”。但是我们希望能够在书籍、网站中找到所需的知识技能,并希望未来会有专家让这些信息变得更准确。
通常我们会假设一切事情都没什么问题,直到出现足够严重的错误,我们再去修正。如果不这么做,现实生活中我们其实很难验证每一件事情都是 100% 正确的。
C. “alert” 面临的理论挑战
“alert” 的问题在于, Satoshi(中本聪)实际上并未实现这个想法。上个月,Eric Lombrozo 也在推文中也提到这一点。
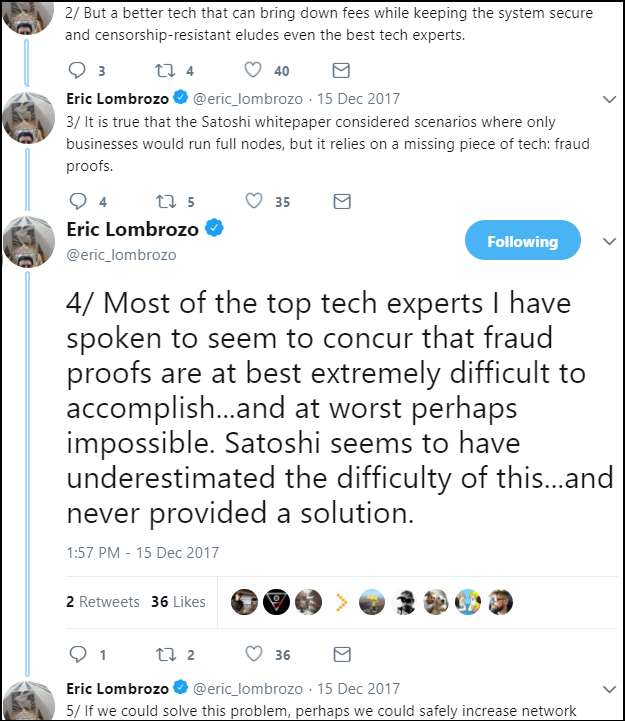
- Eric Lombrozo:“许多我聊过的顶尖技术专家都说,欺诈证明实在是太难实现了,而且在最糟糕的情况下甚至是不可能的。中本聪似乎认识到了其中的难度,因此从未提出过解决方案。” -
若要实现欺诈证明,有两个显然的难题:
- DoS 攻击抗性:比特币全节点之所以对 DoS 攻击有很强的抵御能力,是因为工作量证明机制(Proof of Work)所具备的不对称性 —— 每隔 10 分钟才能产出一个新区块,验证这个区块却只要很短的时间。不过这是否适用于“alert”?“alert” 实行 PoW 机制吗?谁来为服务买单?如果没有人买单,如何阻止恶意节点滥发假的 “alert” 来掩盖真的 “alert” ?
- 无从证明:恶意的/粗心的 矿工可能会丢弃区块内的一部分数据。但是,说极端一些,一个矿工就算完全不知道一个区块的内容,也能挖掘该区块!(译者注:理论上,矿工只需要根据比特币区块头来寻找工作量证明。)如果区块里包含错误交易,我们怎么发现呢?如果没人发现得了,又如何提醒他人呢?
针对第一个问题,我们可以采用区块链以外的方法来抵御 DoS 攻击,也就是支付通道(Payment Channel)。
针对第二个问题,我们可以将(非常宝贵的)“审核资源” 放在验证区块的特定部分 —— 简单来说,我们可以让节点声明自己确实知道整个区块(所有部分)所包含的内容,并使用审计结果来为这个声明背书。
2. 问题
A. SPV 模式
中本聪的 SPV 模式(白皮书第 8 章处):
- 比特币的区块头非常小(每年 4MB 的增量),且易于验证,不受区块所含交易数量的影响。
- 可以很容易地证明,区块中包含了某个东西(某笔交易) “ X ” —— 只要有 “X” 本身、区块头,以及包含两者的有效 Merkle Branch (默克尔分支)即可。
还不太明白的人,可以参考下面的例子:
- - -
假设我们有三个区块头:headerA、headerB、headerC;每个区块头都分别包含一个 hashMerkleRoot (默克尔根哈希):hA、hB、hC。
交易 Tx 是否存在于这些区块( [header A] , [header B] )的任意一个之中?
是的,因为 h( [tx] ) = ht ,且
h( ht, hs1 ) = hi1
h( hi1, hs2 ) = hi2
h( hi2, hs3 ) = hA
其中:
ht 是交易 Tx 的哈希值;
hs1、hs2、hs3 是由全节点(“Fred”)提供的哈希值。
hi1、 hi2 是 SPV 节点(“Sally”)计算得出的中间哈希值。
上述证明的实际含义是,有一棵以 hA 为根哈希值的默克尔树,它有两个分支 hi2 和 hs3,哈希值为证,别无其它可能;hi2 也只有 hi1 和 hs2 两个分支……层层递推,最终可证,ht 必定存在于这棵默克尔树中。
- - -
Merkle Branch(包含了由全节点提供的哈希值,以及这些哈希值在默克尔分支上的顺序和位置信息)非常小,仅以 log(n) 的速率增长。付款者可以轻松 获得/生成 Merkle Branch,并伴随着交易一起发送给收款者;这种成本是可以忽略不计的。
也就是说,只要有比特币区块头,你就能知道 “钱是否已经到账了”。区块头又很容易获得,因此 SPV 模式似乎很容易就能实现无限吞吐量。
B. SPV 模式的问题
问题在于,我们永远无法确定一个 80 字节的区块头是否真的是 “比特币区块头”。
唯一的方法是检查对应区块的全部信息。如果存在一笔无效交易或双花交易(或者说,该区块存在某种 “缺陷”,详见下文的 “区块错误(Block Flaws)”),整个区块就会被视为无效区块。
C. 好消息
虽然我们无法验证一个 80 字节的区块头是否是比特币区块头,但是好在我们能对照当前出块难度,通过计算区块头的哈希值来验证区块头的工作量证明。(区块头设计得非常友好,本身就包含一组重要信息 —— 出块难度和时间戳信息;二者可以相互验证。)
如此一来,我们就能检验矿工是否真的进行了哈希运算;可惜的是,我们还是无法确定这个区块头是否有价值(译者注:即该区块头所对应的区块是否不包含无效交易)。这就好比你托矿工 Matthew 帮你买一盒巧克力,你很容易就能验证 “Matthew 是否真的花了 300 多刀买了一盒巧克力”,但是你无法确定这些巧克力是否好吃,也无法确定它们是否真的含有巧克力成分。
D. 正向/反向 证明回顾
你可以吃掉盒子中的每一颗巧克力,证实每一块巧克力都很好吃,这就是 “正向证明”。
或者你可以顺着以下思路进行反向证明:这盒巧克力是被包装好了的,看起来没有被动过手脚;再加上这盒巧克力有品牌背书,我国又严格执行 品牌法/商标法;已经有很多人买过这个牌子的巧克力,如果质量有问题,我只要随手搜一下就能看到相关新闻/差评(实际上我查了之后,并没有发现任何负面消息)。
另一个采用反向证明的例子是退款承诺。假设你要买辆车(一件不确定质量好坏的商品,就像是新创建出但还未被验证的比特币区块),现在有三款车子(分别为“Car A”、“Car B”、“Car C”),目前你对 Car C 最感兴趣。
若想获得正向证明,你就要把 Car C 开上个数千英里,随行配有一支庞大的机械工程师团队一路检查这辆汽车每个零部件,并汇报问题给你。
如果是反向证明的话:假设 Car A 和 Car B 都提供一个具有法律效力的声明 “里程数不到 40000 英里的车子发生故障,即可退款”;但是 Car C 没有这种承诺,那就反向证明了 Car C 的质量不行。
要实现比特币上的 Fraud Proof,我们需要一样东西 —— 在区块合法的情况下出现;在区块不合法的情况下绝不出现(或者反过来也行)。
在博弈论中,这被称为 “信号博弈(signaling game)”(或更确切地说是 “筛选博弈(screening game)”)中的 “分离均衡(separating equilibrium)”。其中,Fraud Proof 的发送者分为 “诚实” 和 “不诚实” 两类,我们正试图通过低成本的手段淘选掉不诚实的那一类。
E. 我们的需求
我们需要找到一种方法能提醒我们注意 “区块错误”。理想情况下,这种警示要来的又快又准确(即,在“交易结算之前”,或者 “ 6 个区块确认之前“ ,或者(出于安全考量)要在“ 20~30 分钟内”做出响应)。
举个具体的例子,理想情形应该如下:
- “Sally”(SPV 节点)因为某些原因收到了一笔比特币,对方向她展示这笔交易的信息,Sally 也看到这笔交易是合法的。
- Sally 想要在不运行全节点的情况下知道这笔交易是否经过 6 个区块的确认。因此,她先是下载了所有比特币区块头,接着向全节点要了 Merkle Branch (包含【1】她的交易【2】最新区块头)。她得到了一个 Merkle Branch ,然而不幸的是(她根本不知道):里面的区块头因为某些原因是无效的……
- 就在此时,“Fred“ (全节点)必须意识到出现问题了 —— 有一个区块存在一到多个 “缺陷”(详见下文)。
- 必须通过某种激励措施促使 Fred 向 Sally 发起某种警告(即,“alert”)。
- 在其他正常情况下,不能让 Fred 有动力发起警告(即,在没问题的时候不会出现 “假警告”)。
F. 区块错误的类别
区块可能会出现很多种缺陷(详见 validation.ccp, 特别是 “CheckBlock” 一节)。我将它们分为四类:
- “第一类” —— 不良交易(无效交易、双花交易,或是重复的交易)。
- “第二类” —— 区块数据缺失(记录 Sally 交易的默克尔树(Merkle Tree)上,与 Sally 交易所在位置相邻的节点数据处于未知或不可见状态 —— 这可能是人为或无意导致的)。
- “第三类” —— 不良区块(coinbase 错置、版本错误、“见证” 数据丢失, 【或是在 drivechain 上】大量更新了 Escrow_DB/Withdrawal_DB)。(译者注:drivechain 是作者自己提出的一种侧链架构,可见 Peer-to-Peer Bitcoin Sidechains )
- “第四类” —— 不当累加(超过区块大小/ SigOps 限制、coinbase 交易费【必须等于区块内所有交易费之和】、 【在 drivechain 上】侧链的输出—— Escrow DB 的 “CTIP” 字段)。
第一类错误
第一级错误非常好对付。Sally 可以直接通过验证交易并 reversing the outcome (so that “false” validation returens “true”) 来检验该交易的有效性,详见下文。在 SPV 模式下,甚至能检验 nLockTime 和 CSV ,因为 Sally 掌握了 Merkle Branch 和所有区块头。只要观察到两笔交易有相同输入,就能轻松检查出双花交易。重复的交易必然无法通过测试,因为它们必然属于双花交易(除非是 coinbase 交易,详见第三类错误)。
第二类错误
第二类缺陷与 SPV 用户的相关性最强 —— SPV 用户必须假设(除了区块头之外)区块的剩余部分是完整的,但是(根据定义)无法检查是否真是如此。更糟糕的是,矿工可以在不核实区块内容的情况下,创建一个新的区块,他们也确实会这么做。因此,新创建出的区块内可能存在无人知晓的内容,上述假设明显是不合理的。
我将证明,从理论上来说(虽然未经实践证实),只要能向 Sally 提供有效的 “区块头 + Merkle Branch”,就应该存在一个完整的 Merkle Tree(包含 Sally 的交易以及已知一定数量的有效的比特币交易)。因此,所有与区块链数据缺失有关的缺陷(即,第二类缺陷),本质上就是 “Merkle Tree 相关数据缺失” 的问题。可以说,这种缺陷就是未知哈希值原像的问题(易于处理),又或者说的具体点,可以通过对未知哈希原像进行采样来解决这个问题(译者注:一个哈希值的 “原像” 是指被输入某种哈希函数后产生出这个哈希值的原始数据)。
我提出的解决方案是要求 Sally 除了区块头,还需要下载每一个区块的最后一条交易(加上其 Merkle Branch) 2。
第三类错误
第三类缺陷非常普遍,但我相信这种小毛病可以通过一种特定的简单方法解决。举例来说,区块版本如果出错,SPV 节点可以直接从自己维护的区块头中获得正确的区块版本。
其他大多数的信息缺失,可以从 coinbase 交易中找到;因此除了所有的区块头,SPV 节点还需要保存每个区块的 coinbase 交易(译者注:coinbase 即区块中特殊的增发货币的交易)。有了这些信息,SPV 节点就能知道:【1】coinbase 交易是否只出现一次且出现在正确的位置;【2】“见证数据(witness)” 是否存在及见证的内容;【3】确定所有 Withdrawal_DB 和大多数 Escrow_DB 的正确性。
至于 drivechain 的 Escrow_DB,主链 3 上的 SPV 节点必须注意区块中跨链交易的累加影响;解决的方法放在第四类缺陷(本文第7章)介绍。
所以我们要增加一些开销 —— 引入 “ SPV + ” 模式(又称为 “ SPV 补丁”)。“ SPV + ” 节点除了要同步比特币区块头(每十分钟增加 80 字节),还要同步每个区块的第一笔和最末尾交易,外加与这两笔交易相关的 Merkle Branch。
- 旧式【中本聪的古典 SPV】:同步区块链中每个区块的区块头(80 字节/区块);每收到一笔新交易就进行一次汇总(交易 & Merkle Branch)。
- 新式【SPV + 模式】:80 字节/区块 + (coinbase 交易 + 区块中最后一笔交易)/区块 + 两个(不相同的)Merkle Branch /区块;每收到一笔新交易就进行一次汇总(交易 & Merkle Branch); 与其他几个节点建立支付通道。
SPV+ 模式会增加多少存储开销?我不确定,但假如 coinbase 交易约 1000 字节,“最末尾交易” 约 280 字节,每个区块约装有 5000 笔交易,那么同步一个区块的开销就会提升为 2192 字节/区块 4,而不仅仅是 80 字节,而且开销的增速不只是 O(1),会大幅提高到 O(log(n))。
按照一年约产出 52596 个区块,因此存储花销会变为约 115 MB/年,不只是 4 MB/年。这看似大幅增加开销,但从全局的角度来看,SPV+ 仍然是非常节省的方案。如果 Sally 想要完整地检查交易有效性,她只需要对每个区块多下载这些数据:(可以是)最近六个月产出的区块,或是那些记录她收到比特币的区块(以及这些区块的前后 ~10 个区块),以及(或是)一些随机的检查信息。
第四类错误
第四类缺陷非常有意思。本文第 7 章会介绍如何将第四类缺陷转换成第一类缺陷,不过简单讲,要解决第四类缺陷,我要求交易哈希值不仅仅作为交易自身的保证,还要说明自己 对累加指标造成的影响。举例来说,交易不仅要保证自己是 “277 字节”,还要说明 “加上自己之后,宿主区块大小从 500809 字节增加到了 501086 字节”。这样一来,所有的 “假交易” 就能被孤立且识别出来了。也就是说,最末尾交易会提供很重要的信息(交易总数、区块大小、总体交易手续费,等等)。
在我深入更多技术细节之前,为了避免有人因为听不懂而掉队,我将以故事的形式再次说明 “整个逻辑”。
3. 讲个故事
故事由“ Fred ”(全节点),和“ Sally ”(SPV 节点)主演。为了简化,故事聚焦于第一类缺陷和第二类缺陷。第三类缺陷需要通过下载额外的数据来解决,第四类缺陷能够转化为第一类缺陷(见第 7 章)。
对话 I
- Fred:“这笔交易是你要找的嘛? Wow,这笔交易记录了 —— 转给 Sally 300 btc!”
- Sally:“是的,我卖给 Peter Thiel 一艘太空船,他能去木星啦。”
- Fred:“赞哦。这是你需要的 Merkle Branch,还要有最近一段时间的所有区块头。”
- Sally:“太好了,我可以简单计算几个哈希值来检查 Merkle Branch,也能轻松确认这些区块头都满足难度要求。赞美中本聪!”
- F:“中本聪牛啤 !”
- S:“不过,我要怎么确定这些区块头是合法的呢?没准这些区块头来自恶意 or 懈怠的矿工。Peter Todd 说过 SPV 节点很烂 ……。”
- F:“噢,那你可能会对我的一些附加服务感兴趣。”
- S:“说来听听?”
对话 II
- F:“第一项服务叫 ‘无效交易保险’(Invalidity Insurance),你需要支付 0.007 刀给我;假如你通过 hashMerkleRoot 发现区块中有无效(或双花)交易,我会理赔你 1000 刀。”
- S:“任何区块错误都会理赔吗?”
- F:“没错,任何类型的无效区块都能理赔。”
- S:“哇,看来你非常有把握缺陷不会发生,不然你不会愿意这么做的。”
- F:“因为我已经用电脑检查过所有区块和其中的所有交易;它们都是有效的。”
- S:“有意思!”
- F:“提醒一下,如果 12 小时内(72 个区块之后)你没有发现任何问题,你的保险也就到期啦。”
- S:“我明白了。不过这个区块会在 10 分钟内完全传播到整个网路中的全节点对吧?”
- F:“对,而且你要想想,12 小时可比 10 分钟足足长了 72 倍呢。”
- S:“这么说也是,只要全节点有动力将 “某区块有缺陷” 的消息传出去,12 个小时肯定足够传播给所有人了。”
- F:“对的,激励的存在至关紧要!”
对话 III
- S:“等等,也许你给我的不是完整的区块?我听说矿工有时候会无脑出块,完全不管里头的内容是不是有效的!如果他们这么做会如何?我们又有什么方法能够检查呢?”
- F:“Hmmm,我这里保存的的确是完整的区块。”
- S:“真的吗?”
- F:“千真万确。”
- S:“你能不能提供证明?”
- F:“当然,实际上这是我提供的第二项服务。”
- S:“太棒了!”
- F:“首先给你这个,这是该区块的最末尾交易。你可以相信我,因为这棵 Merkle Tree 始终向右下延伸;如果出现了向左延伸的情况,那就说明我们给同一对象哈希了两次,也就是在默克尔树的那一层原本只有奇数个对象(译者注:已经没有相邻的节点可以一同哈希,只能将自己再哈希一次)。你可以将这个 Merkle Branch 和我前面给你的 Merkle Branch 进行对比,他们会有相同的 Merkle Root。”
- S:“没错!你给我的的确是这个 Merkle Branch (包含我的交易)中的最末尾交易。”
对话 IV
- F:“这棵 Merkle Tree 有 11 层,所以你知道这个区块中至多有 2^11 = 2048 笔交易。而且你知道自己对某对象做哈希运算的次数以及时间,所以你知道 Merkle Tree 的外观。尤其是,你知道它里面装着的东西的确切长度(大小)。”
- S:“Wow,原来我知道的事情比我想象得多!我真的知道所有内容吗?”
- F:“当然!”
- F:“Merkle Tree 中所有东西的位置必然相同,否则无法匹配 —— 除非某人能找到一个 X ,对其进行两次哈希计算所得到的哈希值要与一笔 “真实交易” 的哈希值相同;换句话说,“不平衡的 Merkle Tree ” 要求创建者找到这么一个 X,使得 h(h(x)) = h(真实交易)。但这就像要找到“哈希碰撞“(理论上行不通)——因此不可能找到 X。
有趣的是,一个东西不可能既是 Sha256 哈希值又是合法的比特币交易。比特币小白可能不知道:最小的比特币交易大小为 60 bytes(比 32 byte 的哈希值体积要大得多)。
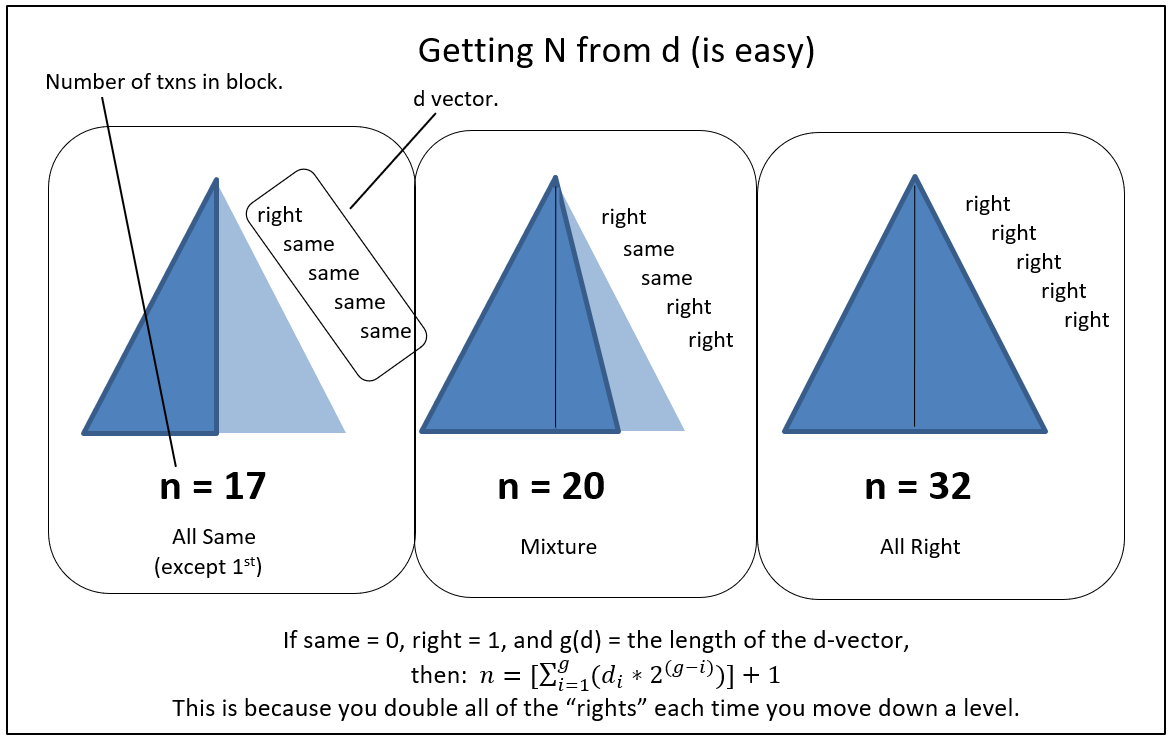
- S:“我明白了——当不存在重复交易的时候,Merkle Tree 在几何上就像个等腰三角形;当最末尾交易被复制多次的时候,Merkle Tree 看起来像直角三角形。最后一笔交易所在的深度,就是整棵 Merkle Tree 的高度,根据重复规则,我只要知道右边缘啥样,就能知道有多少底部元素(三角形最底层的元素)是重复的。“
- F:“包含你这笔 300 btc 交易的区块,它的 Merkle Tree 深度为 11 单位——也就是三角形高度是11层。通过我给你的最末尾交易,你知道区块只在最后进行了一次重复哈希计算。这样一来,你就能确定这个 Merkle Tree 包含了 2047 笔交易。“
- S:“噢,解释的好清楚。如果今天 Merkle Tree 深度为 10 单位,所有交易(当然,第一笔交易除外)都只做了一次哈希计算,那么我就能知道这个区块有 513 笔交易!“
- F:“没错!“
- S:“Wow!“
- F:“假设我现在给你新的 Merkle Tree,以及带了 Merkle Path = [A, (self), B, C, (self)] 的新的 “最末尾交易”,你能知道什么?
- S:“它有 5 层,而且共包含 23 个独立的元素。“
- F:“完全正确!“
- S:“我真的学到好多。“
- F:“还有最后一件事:每个最终的元素要么已知,要么未知;在已知的情况下,这个元素可能是合法的交易或不是合法交易。整理一下,区块中包含的所有元素可以分为【1】合法交易;【2】非法交易;【3】一条没人能看见的消息。“
- S:“嗯,很直观!“
对话 V
- F:“好的,现在你能看到你的区块内有 L = 2047 笔交易。“
- S:“对!“
- F:“现在介绍我的第二项服务:你只需要支付 0.0001 刀—— 比刚才还少。你可以随机从 1 到 L 中挑选一串整数 5,然后我会给你对应的交易和 Merkle Path。如果我做不到,那我会赔偿你一大笔钱。”
- S:“你好像很有自信呢!“
- F:“那当然!你可以找你的智囊团,研究出我可能遗漏的交易。不过我保证,你们绝对找不到。“
- S:“好,这个服务我也要了!“
- F:“还有件事要注意,如果我们达成协议,但你不告诉我你选的整数 6,别人还是会以为我没完成挑战对吧。我的意思是,我完全有能力展示你要看的交易,但你不说要看哪个,所以我没法展示。所以如果你没有在规定的时间内给我你的选择,我要收取全额的查询费用,甚至更多!“
- S:“ Emmm,好吧,我想对于我这笔 300 btc 的交易,我不应该吝啬于锁定一定数额的查询费用。“
- F:“相信我,你只需要锁定几秒钟。换做是我也不愿意自己的钱在任何时间点,被毫无意义地锁在某个通道里。“
- S:“ Ok!“
- F:“好的,现在我们的支付通道处于状态 (A, B),你需要创建状态 (C, D),等我们迁移过去之后再告诉我你选择的整数串。“
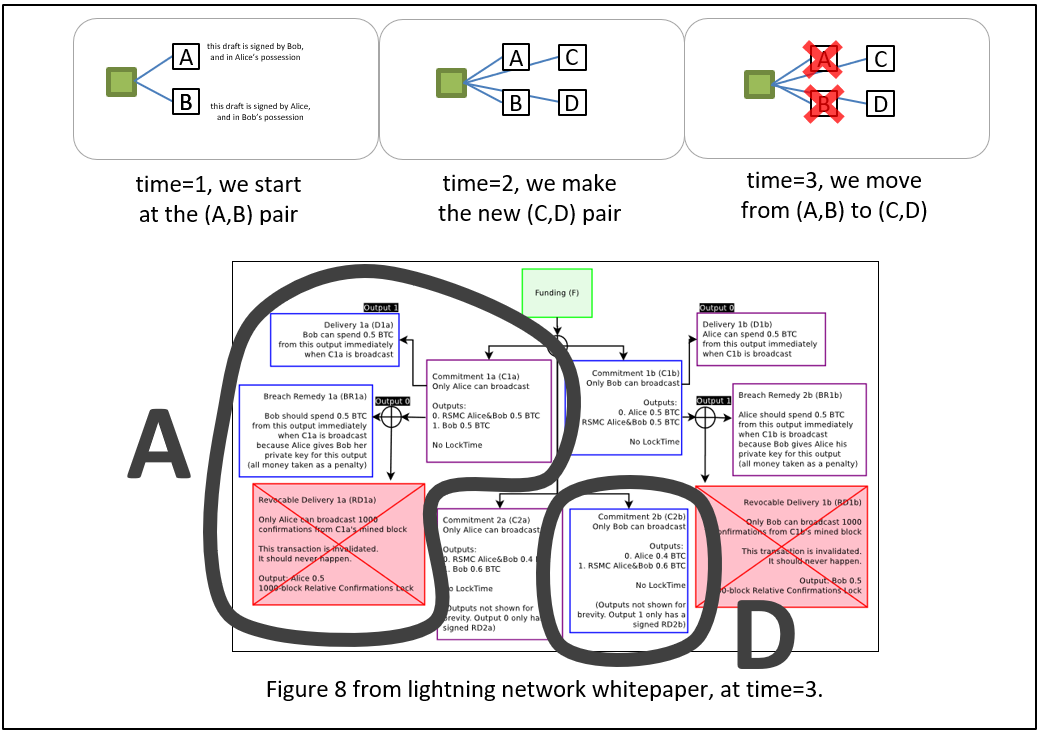
对话 VI
- S:“好,我已经选好了一些 Rs(随机数),也创建好了 C 和 D(支付通道的下一个状态)。来,我将 D 签署给你,轮到你行动了。“
- F:“谢谢!Hmmm……看来你把所有内容都按照所需格式填写正确了。“
- S:“给,这里是我选择的随机数……“
- F:“慢着,慢着!你等会儿再给我啊!“
- S:“噢,不好意思。“
- F:“没事。“
- S:“还有个问题,如果我向你展示的是 Rs 的哈希值 Hs,你有什么方法确定 R 是否遵循规定呢?我有可能不在(1,L)的范围内选择整数,我有可能不是选择(5, 470, 4,……),而是无意义的随机字符(‘ fish ’, 0x78965, ‘_’, 987987987, ……)。当你拿到这样的随机数,你不可能返回对应随机数 “fish” 的交易给我对吧!? “
- F:“啊 …… 这是个好问题。事实上,有很多专业的密码学家提出很多种方法应对这个事。我会选择其中一种方法,要求你要向我发送 “Gs” 而不是 “Rs”。”
- S:“好的,我已经用选择的 Rs 生成了 Gs,给!“
- F:“嗯,从你给我的 Gs,我可以确定 Hs 的确是从范围(1,L)选取的整数。因为我有所有的 L 条交易,我很自信能满足你的挑战。”
- S:“太棒了,那下一步呢?”
对话 VII
- F:“来,给,这是我签过名的 C。我已经把 B 弃用了(根据支付通道迭代规则)。”
- S:“好的,不需要我也作废 A 吗?”
- F:“需要,但即使你不这么做,我还是能广播 D。”
- S:“如果我抢先把 A 广播出去呢?”
- F:“这就相当于这次服务从没发生过 ……”
- S:“啊哈,那我可以作弊啦!既然你愿意接受挑战,那你肯定知道这个区块是合法的!”
- F:“(摊手)啥意思?”
- S:“……(你要是不知道那个区块是合法的,就不会愿意接受挑战了,那么你一接受,我就已经得到了我想要的)也就是说,现在我已经得到想要的信息,而且不用支付任何费用啦!”
- F:“并不,虽然你知道我已经接受挑战,但你无法确定我是不是真的有能力完成这个挑战对吧。”
- S:“……(沉默)”
- F:“你要明白,在开始这个过程之前,我只是 接受挑战 而已。看来你还有要学习的地方,不然我不明白你现在退出是图什么。”
- S:“……(沉默)”
- F:“也许我猜到你会想退出,所以事先做了份假的审核,实际上我根本不知道这个区块的有效性。”
- S:“……(沉默)”
- F:“对比一笔太空船的价格,万分之一刀真的是少到不能再少了。”
- S:“好好好,我已经作废 A 了。”
对话 VII
- F:“OK,你现在可以说出你的 Rs。”
- S:“我选择的是 453、531、14,和 2011。”
- F:“选的好!这里是你要的交易 #453、#531、#14,和 #2011;还有它们对应的Merkle Branch。你可以看到,我的确有该区块的完整交易。”
- S:“太酷啦!我爱 Fraud Proof。”
在介绍无效交易保险(Invalidity Insurance)和完整性审核(Fullness Audits)之前,我想先回顾一下支付通道和闪电网络。
4. 支付通道概述
A. 常规(无通道)支付
常规(无通道)支付的含义是,表示资金转移的 “消息” 会在网络中传播,一旦消息被记录到区块链上,资金转移即告完成。
就像现在朋友 A 发了封邮件,告诉你 “我的 12 个 btc 有 4 个是你的了”,然后你点击 “回复所有人”,声明 “我的 4 个 btc 中有 2.7 个是老 Q 的了”。一旦这些 “邮件” 的副本进入了区块链,这些邮件对应的交易就被认为已经发生了。
B. 支付通道
要使用支付通道,收付双方首先要使用自己的 btc —— 把钱 “存入”(或者说 “创建”、“开启”)一个通道,然后再付还给自己。例:我拿出 90 btc 然后付还给自己,你拿出 15 btc 然后付还给自己,这些操作合并为一笔交易,就像其他普通交易一样广播出去。
不过,虽然开启通道的操作是类似的,参与者在通道中的收付行为可能有所不同。
沿用上面的类比:所谓的支付通道模式就是,在我们发送 “电子邮件” 之前,我们保留了多个未发送的 “邮件草稿”。对于同一份草稿,始终存在两个并行的版本 —— 我手上会有一份对你更有利的版本,而你手上也会有对我更有利的一个版本 —— 你已经对我手上的那份草稿签过名,我自己还没签名;反之亦然,你手上的那份草稿我已经签名了,但你自己还没这么做(签名)。
C. 更新支付通道
支付通道参与者将共同通过切换状态(我称之为 “势能(potential)” 状态和 “动能(kinetic)” 状态)来循环更新平行的草稿对。
通道大部分时间处于静止、无变化的 “势能” 状态。一旦有人要更新这个通道,状态会切换成 “动能” 状态,然后再快速切换回“势能”状态。
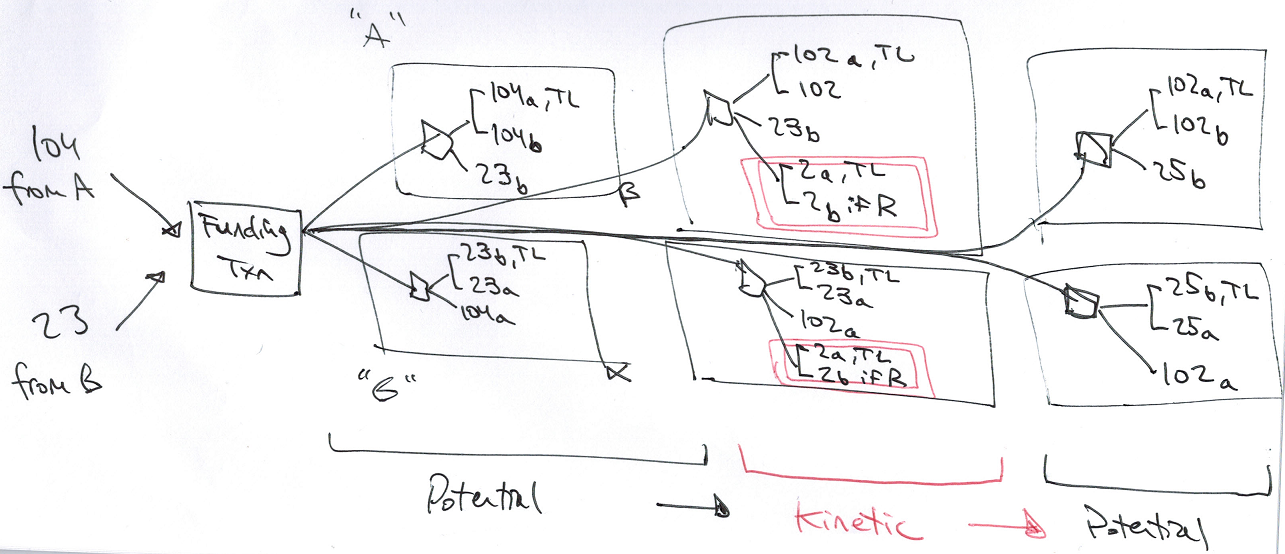
上图:“动能” 状态——2 btc(粉色,双框)正等待被触发,但实际上这个过程非常短暂。通道大部分时间处于“势能”状态,反映了各方最新的 btc 余额是多少。
如我前面提到的,如果 “区块链” 记录了这些“邮件”的副本,那这些交易就已经发生了。
但支付通道不一样 —— 当双方共同从一对草稿 “转移” 到新的草稿,这笔交易就被认为是发生了。而且,“转移” 过程本身也大不相同 —— 并不是说我们一起创建、签名、交换了新草稿的数据就算完成了 “转移”;我们还必须采取额外的步骤来创建、签名和交换 “表明弃用旧草稿对的信息”。只有到那时候,付款才算真正“发生”。
D. 哈希锁定合约/闪电网络
我们一般说的 “动能” 状态,也称为“哈希锁定合约(hash locked contract)”。当部分动能状态,通过支付通道的通路(即人际网络)分享出去,就能建立起 “闪电网络( Lightning Network )”。细节如下:
- 有个 “顾客” 要付 10 btc 给 “店家”。
- 顾客创建一个秘密随机数 R,以及 R 的可公开版本 H 。H 就是 R 的哈希值,h(R)。
- 顾客找出一条能使自己与店家连接起来的支付路线,把 H 发送给这条支付路线上的所有人 7。
- 顾客沿着条 “通路”,向边上的 “朋友 #1” 发出一个动能更新;特别的是,顾客承诺,如果 “朋友 #1” 能猜出 R 是什么,顾客会向他支付 10.004 btc。
- “朋友 #1” 不知道 R ,但是他确定很快这个 R 就会被公布,而且他也不会有任何损失,因此朋友 #1 兴冲冲的接下这个活。这时候,【顾客,朋友 #1】间的支付通道就被激活了,从 “势能” 状态转为 “动能” 状态。
- 接着“朋友 #1” 和 “朋友 #2” 重复上述行为,在整条【顾客,店家】通路中,朋友 #2又比朋友 #1 更靠近店家。如果朋友 #2 能够猜出 R,朋友 #1 会向其支付 10.0003 btc。
- 整个过程继续重复进行,朋友 #3 会得到 10.0002 btc、朋友 #4 会得到 10.0001 btc;最后,只要商家能猜到 R是什么,他就能从朋友 #4 那里得到 10 btc。
- 现在整条通路已经完成了。顾客把 R 发给商家,商家就能凭 R 向朋友 #4 索取 10 btc。
- 商家向顾客发货。
- 商家和朋友 #4 不想用常规交易来支付(这会需要付交易手续费,而且要等待)。因此商家向朋友 #4 展示 R ,要求更新支付通道的状态。接着支付通道状态就从 “动能“ 状态转回 ”势能“ 状态,只不过在新的势能状态下,商家多了 10 btc,而朋友 #4 少了10 btc。
- 其他的通道对也重复进行步骤 10 。(【朋友 #4,朋友 #3】、【朋友 #3,朋友 #2】、【朋友 #2,朋友 #1】、【朋友 #1,顾客】)(译者注:即每个从下家处拿到 R 的人都向上家要求兑现承诺,直至最后一个中继者(即 “朋友 #1”)从 “顾客” 处得到最后一笔的支付)。
E. 灵活性
有趣的是,动能交易可不止是 HTLC(即 “你给我出示 R 我就给你付款“)而已。闪电网络交易(LN-txn)能完成基于区块链的一切行为。
我们首先要求区块链能做两件事:“无效交易保险“和“完整性审核”。只要底层区块链能够支持这种 “智能合约”,我们就能将其应用到支付通道中。
F. 支付通道解决了什么
支付通道能帮助实现欺诈证明,因为:
- 能以接近实时的速度进行需要的操作,帮助 Fraud Proof 在关键的 20-30 分钟内“获取足够的信息”。
- 协助小额的交易(支付非常非常小的金额)。
- 可抵御暂时的出块错误(因为它们有较长的 “挑战窗口期”)。
- 通过以下行为支持反向证明:【1】索要某些信息,【2】为此提供小额奖励,【3】给对方足够长的时间来提供它。当然,如果他们没有接受挑战,那很有可能是因为他们无法完成。
现在我们可以来介绍 “无效交易保险” 和 “完整性审核” 了。

- Max Pixel 的河流艺术作品 -
5. 无效交易保险(Invalidity Insurance)
第一个解决方案算是两个解决方案的简化版。(好吧,也许我该让你们自己来判断。)
A. 概述
无效交易保险是一笔支付交易(即是一个比特币脚本),仅在某个区块被证明包含第一类错误时才会生效(区块由其哈希默克尔树根值 8 来定义)。
这种支付交易的受益方需要提供 4 个东西:
- 哈希默克尔树根值(hashMerkleRoot,缩写为 “hMR”);
- 一笔 “不良交易” —— 因某些原因应被判定为无效的某笔交易的 TxID;
- 一个默克尔分支(如此处所述,由分支长度、分支哈希值及分支方向构成),能将不良交易与 hMR 关联起来;
- 证明交易无效的证据。
B. 证据类型
第四个东西(“证据”)还会因交易所属的错误类型不同而有所区别。不良交易可分为 4 种:(a)无效交易;(b)双花交易;(3)重复交易;以及第四类错误,(d)“错误累加(bad accumulator)”(见第 7 章)。
- -- -
边注:Fraud Proof vs. 智能合约 Fraud Proof
在继续推进以前,我希望对比一下 “现有的 Fraud Proof” 与 “可以在一笔比特币交易中使用的 Fraud Proof”。
我的目的是实现后者,因为它是一种双赢的技术:首先,我们能获得 Fraud Proof;其次,它也给了我们一种激励兼容的办法,让我们能够便宜地从全节点处购买到这些 Fraud Proof。
实际上,我们确实需要双赢的局面,因为我想解决的不仅是 “如何构造 Fraud Proof” 的问题,也是 “保证 Fraud Proof 供应” 的 搭便车 难题。
让比特币自身能理解其 Fraud Proof 的好处是,我们可以把 Fraud Proof 放进交易中,并在比特币智能合约中使用它。但这是非常难实现的。我绝对不打算假装自己已经找到了最佳答案 9。
- - -
(a)无效交易
乍看起来,我们似乎只需要用协议的交易验证函数把交易再跑一遍,要是函数运行 失败 10 就能证明该交易无效,因此,似乎只需要把交易自身作为 “证据” 就可以了。
但是,我认为没有那么简单。这里面有个难题!
如你我所知,跟比特币相关的每一棵默克尔树都包含可能是有效的交易,但是,树上也包含它自身的内部节点(interior node)!如果 Sally 的默克尔树声称某笔交易是无效的,然后她给我们展示了一个路径,指向 “两个串联起来的 32 字节的 SHA256 哈希值”,我们能怎么看呢?我们怎么知道这些字节代表的一笔无效的比特币交易?Sally 的路径所指向的 node 可能并不代表一笔交易,她有可能在默克尔树的树高上说谎了!
或者相反的情况也有可能(比如恶意的 Fred 故意构造了一笔无效的交易,该交易的形式刚好是 64 个随机字节),到底是谁在骗谁?
为解决这一难题,我们要求 Sally 同时还得提供一个默克尔分支,来证明别的一些交易是有效的。为了方便程度最大化,可以就是她自己的交易(也就是她在收款时的交易,就在 Fraud Proof 交互过程刚开始的时候发生的),或者,也可以是 coinbase 交易(她的 “SPV+ 节点” 本身就会保存 coinbase 交易)。
因此,在这个方案中,给定一笔是无效的,证据至少要包含两笔交易,一是该无效交易本身,二是一笔有效交易,且两笔交易的默克尔分支高度必须相等。
如此,则(a)所需的证据形式与下文的 (b)和(c)所需的很相似。
(b,c)双花交易和重复交易
对于(b)和(c)来说,欺诈的证据似乎也很直接,只需要两笔交易和两个分支就够了 —— 然后我们就可以看到两笔交易的输入(或者哈希值)是一样的。
但是这里又有一个陷阱,就是第二笔交易的位置!(我这里的 “第二笔” 的意思是按时间顺序算的 “第一笔” 交易,也就是某人尝试双花的那笔 “真正” 的 交易/资金)。该笔交易可能存在于另一个区块中。
实际上,两笔交易的位置可能远隔成百上千个区块。
如果脚本解释器可以访问过去的区块头,那我们也许可以完成证明工作,只需加多一个 32 字节的哈希值就好。但我不知道完成这个事的最好办法是什么 —— 也许是一个新的操作码,会在验证出某个 32 字节的哈希值不在已知的哈希默克尔树根集合中时传出失败。
如果我们没有高效的办法,那么在最糟糕的情况下,处理方法就非常烦人 —— 要加入一整条连续的区块头链条,从双花交易所在区块的区块头一直追溯到第二笔交易所在区块的区块头。当然,后面的事情就比较简单了,要求包含一个 “三件套” (区块头、默克尔分支、交易)来证明一笔有效的交易已经花费过那笔资金(对应(c)时,则是一笔具有相同哈希值的有效交易)。
可怕的是,如果双花交易所花费的资金是在数年前已经花费过的,则我们需要几十万个 80 字节的区块头来完成证明。这样一个区块头链条自身的数据量可能就是 16MB!这么大的数据量根本塞不进一笔交易里面。现在,这里需要提升。
实际上,有些人,包括 Blockstream,曾经撰文讨论过如何把一百万个 80 字节的区块头压缩成 “几十 KB 的数据”,等等。(见附录 B)
如果你知道该怎么处理这个问题,请留下你的评论!
(d)错误累加
对于(d)类不良交易,比特币需要一种办法来理解交易中数据的 “累加器”(或者说 “第二见证数据”)。网络需要根据交易的属性来检查这些数据。细节在本文第 7 章。
(重复一遍:用软件很容易实现,但要装进比特币脚本中就难很多。)
C. 汇总一下
有了这个脚本,我们可以策略性地部署在支付通道中,以保证不会收到无效的区块头。
具体来说,对每一个区块头,我们都将把一个通道推入 “动能” 阶段,使得:
- Sally 无条件给 Fred 支付一笔钱;并且
- Sally 可以从 Fred 处得到一大笔钱,只要她能找到一些证据,证明相关区块头是无效的。要不然,一段时间(比如 1000 个区块)之后,Fred 就会收回这笔钱。
前面那笔资金有点像保险费,而第二笔资金像是保险理赔 —— 只要条件满足,Sally 就有权得到赔付金,不然,Fred 就可以收回这笔钱。
一个诚实的 Fred 完全有信心接受这种交易。对他来说,因为绝对不可能找到他所提供的区块头无效的证明,因此他永远不用赔付,而保险费简直就是天上掉馅饼。
因此,这里的 “Fraud Proof” 是通过相反的方式来实现的:如果这种类型的交易没有人愿意签署了,那我们就得到警示了。
不过,在一种情况下,不诚实的 Fred 还会继续提供这种服务,我们在上文所述的故事里提到过,就是交易数据丢失的情况。不诚实的 Fred 知道,如果全网都丢失了某笔交易的数据,Sally 就不可能证明出其中的欺诈。因此,提供了相关服务的 Fred 也就永远不会被抓到 —— TA 犯罪的证明已经荡然无存,那 Sally 还凭什么送 TA 去监狱呢?
这就是为什么我们需要完整性审计(Fullness Audit)。
6. 完整性审计(Fullness Audit)
完整性审计使得 Fred 可以(向 Sally)证明他确实拥有一个区块中的所有交易。
A. 两种材料
首先,我们需要一种新的 “魔法材料”,用于把 “一个整数” 转化成 “默克尔路径方向” 并返回。
有趣的是,我们已经有这种东西,无需再费手脚了。这个方向已经作为单个 int32_t 值存储下来了(反正,Namecoin 的合并挖矿要用到)。甚至可以断言,这个值 “……就等于所在默克尔树最底层起始哈希值的索引”。这里用到的是整数的二进制编码原理!所以,问题解决了。
我们需要的第二种魔法材料,“范围证明/集合成员证明”,让我们可以利用链下交互(可能你在阅读本文第 3 章时已经注意到了)。所以这个问题也基本上解决了。
我再加一句,现在有一支比特币顶级密码学家天团在全身心投入研究 “范围证明”,不过理由与我们这里的不相干(他们想把范围证明直接用在链上,用来隐匿比特币交易的金额)。相较之下,我们的用法柔和得多。
如果你认为你有一个绝佳的承诺方案,请留言告诉我(可阅读下文的 “(3)保险理赔” 了解更多细节)!
B. 汇总一下
链上发生的步骤如下(或更准确一点来说,是发生在支付通道的内部的事情,但这些指令可能随时需要上传到链上):
- Sally 给 Fred 无条件地支付一小笔钱。这是 Fred 要求的费用,或者说 “保险费”(数额很小的,因为保险条件是 Fred 明知绝不可能发生的情况)
- Sally 要给 Fred 支付非常大一笔钱,如果 Sally 坐等时间流逝,迟迟不公开 TA 的秘密 “R” 的话。这个金额一定要大于下面的保险理赔金额,以保证 Sally 会及时交互。有点像是 “诚意金(fidelity bond)”。
- 如果 Fred 不能提供 Sally 所要求的区块数据的话,TA 要给 Sally 支付一大笔钱。这就是 “保险理赔金”。
(1)保险费
保险费的数额非常小。通过普通的支付通道更新来传递。
(2)诚意金
要实现诚意金也很简单,尤其是在闪电通道类型的通道中,因为它是 “哈希时间锁合约”。举个例子,Sally 先发送 10 btc 给 Fred,这笔资金充当 “人质”。其次,Fred 把钱转回给 Sally,当且仅当 Sally 在 “时间锁窗口” 内公开了 R(即,一旦公开 R,就释放人质)。那么,如果 Sally 没有公开 R,TA 就等于是交了 10 btc 的罚金。
如果 TA 公开了 R,TA 就能拿回 10 btc,然后 Fred 就拿到了 R,他可以自由用在某笔交易中。如上所述,诚意金必须是这几笔资金中金额最大的,而且其时间锁要短一些,因为还有一个针对 Fred 的时间锁(见下文),其长度要比诚意金时间锁长一倍,以保证 Fred 也有足够长的时间来提供区块数据(即,在 Fred 获得了 R 之后,最坏也还有一个完整的时间锁周期来完成任务)。
(3)保险理赔
实现保险理赔要难一点。
保险理赔的形式与诚意金一样,只不过人质是 Fred 的资金,而不是 Sally 的。只有提供与 R 相关的区块数据,TA 才能拿回自己的钱。
我分两部分来说明这个合约。第一部分是确认合约的初始参数:
- Fred 必须提供两个整数 (X, R),并且承诺 c(X, R) 可以匹配一个预先设定好的哈希值 H1,而 hash(R) 匹配一个约定好的 H2。H1 和 H2 的值都是由 Sally 在选择自己的随机数并更新通道状态的时候提供的。
- “X” 是一个默克尔树索引值(请看上文的第一种 “魔法材料”),而 “R” 是一个随机的 256 位的整数,是由 Sally 自主选择的。
- Sally 为了拿回她的 “诚意契约金” 就会公开 R
- 最后,Fred 可以用 R 来求得 X(只需 L 次哈希计算,L 为该区块所装载的交易数量),然后提供 (X, R)。
很简单吧?但第一部分还有最后一个要求:
- Sally 必须给 Fred 作出承诺,或者说提供范围证明(在链下,实时交互,体积大小任意):X 必然落在 (1, L) 范围内。
- (所以这个承诺可能无法采用哈希值的形式。那么这就可能需要脚本的版本控制,或者一个新的操作码,或其它更为高级的技术。又或者只包含代数范围。抱歉,找出最合用的工具非我所长,问问 Andrew Poelstra。)
第一部分只是确认 “Fred 同意要做什么”。Fred 还没有真正着手去做!
所以,为了满足合约的条件,Fred 需要:
- 将 x1 解释为一个默克尔树索引值,然后提供一个默克尔分支,既有同样的索引值,且最终的哈希值是 “H3”,即他们正在测试的区块头的哈希默克尔根值。这样 Fred 就证明了,无论 Sally 选择的随机数是什么,Fred 都可以向她出示相应的哈希值。
- 最后,Fred 还必须提供这个哈希值的原像。
一句话:要是 Fred 可以出示那个原像(产生出相应哈希值的原始数据),TA 就过关了。否则就不过。
如果原像是一笔有效的交易,那么皆大欢喜。如果原像不是一笔有效的交易(比如就是一个乱七八糟的数据),那 Sally 就大可利用第 5 章所述的 “无效交易保险” 来赚一笔了。两个服务是相互补充的。
C. 重复审核
显然,Sally 能抓到欺诈的概率并不高:只有 1/L。所以,Sally 可能希望多次尝试。而 Fred 应该也很乐意,因为每次审核 TA 都有钱进账。
D. 【可选】关于丢失的数据
自上而下与自下而上
我们可以把默克尔树(在视觉上)想象成一个巨大的三角形。一般来说,这个三角形是 “自下而上” 搭起来的,最底下那一层是最先搭好的,而 “顶部” 是最后完成的。顶部的值(也就是默克尔根)会放到区块头里。
全节点总是这样自下而上来搭建这个三角形的,原因如下:【1】全节点一般都拥有全部的底层数据;【2】三角形上,除了最底层,每一层的数据都取决于其底下一层的数据。
但 SPV 节点也可以选择用 “自上而下” 的方式来搭建三角形,就是从默克尔根往下延伸。这样他们就既不需要保存整棵默克尔树,又能 “瞄中” 这个三角形中某个位置的准确数据。
(这种模式对正在下载和验证一个新发现区块的全节点来说也有用。因为全节点需要存储(最新一些区块的)整个三角形 —— 所有中间层的哈希值都要保存。)
“整个三角形”
那整个三角形到底有多大呢?看表:
| 默克尔树深度(高度) | 该层的数据个数 | 总计数量 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 3 |
| 3 | 4 | 7 |
| 4 | 8 | 15 |
| 5 | 16 | 31 |
| 6 | 32 | 63 |
可看出,设第一列的值为 “n”,那么第二列的值就是 “2^(n-1)”,第三列的值就是 “(2^n)-1”。
所以,第三列的值(也就是 “整个三角形” 的大小),差不多总是第二列值(“三角形” 的底层)的两倍大。所以,如果我们存下整个三角形,而不是只存底层,存储(哈希值的)所要求的空间只不过增加了一倍。
而且,全节点存储着所有的交易,还有交易的哈希值。如果一个区块的大小是 8 GB,因为一笔交易的数据量大概是 250 字节,那么区块中大概会有 32,000,000 (3200 万)笔交易,那么 “三角形底层” 的大小是 32,000,000 * 32 byte(一个哈希值的数据量),就是 1.024 GB。根据上面的逻辑,三角形的其余部分也会占去约 1.024 GB,所以,全三角形存储模式所要求的内存空间及硬盘空间是 10.048 GB,而不是 9.024 GB。
(而且,一旦获得了整个三角形,存储要求会回落到 9.024 GB)。
审核三角形
一个遵守协议的 Fred 可以获得完整的三角形,但丢失了一些数据的 Fred 就做不到了。TA 甚至可能遗失一些 “从中到上” 路径上的值,这就更容易被发现了,因为数量上要少得多。
实际上,Sally 可以要求任意的一个哈希值,具体在树上哪个位置无所谓,只要是在树上的就行。
要通过这样做来审核三角形的完整性,TA 可采取跟我上文所述完全相同的步骤!只不过最后一步不是公开一笔比特币交易,而是两个 32 字节的哈希值(Sally 不能把这个数据用在无效交易保险中,恰好相反 —— TA 会认定这是 Fred 拥有整棵默克尔树的证据)。
7. 第四类错误(不当累加)
迄今为止,我还未讨论到区块错误中的一个完整类别 —— “第四类错误”。对第四类错误的担忧涉及到了一个包含众多交易的区块的方方面面。
我会现解释这类错误,然后提出一种办法来将它们转化成 “第一类错误”。
A. 涉及多笔交易的证据
考虑一下违反区块大小限制的情形 —— 这个臭名远扬的规则要求一个区块内 所有 交易的 总体积 不得超过某个限度。如果恶意的 Fred 创造了一个过大的区块,比如【非见证数据的】体积达到了 1.0001 MB 的区块,那 Sally 怎么意识到这一点呢?
(仅仅只是为了让解释尽可能简单和清晰,我使用 SegWit 升级以前的 1MB 和 20000 限制。没有别的意思。)
我们迄今为止提到的所有技术,没有一个派得上用场。即使一个区块内的每一笔交易都是有效的(第一类方法无用),并且也都可得(第二类方法无用),第四类错误仍可能发生。而仅凭 “SPV+” 模式不能帮我们解决这个问题(因为获得了 coinbase 交易也没什么用)。
尤其是,无效交易保险只接受将 单笔交易 标为错误的证明。但第四类错误根本不在 “交易层面”,它是 “区块层面” 的。
所以,任何在 “区块层面” 的规则,诸如 区块大小/SIGOPs 限制,我们都检查不到。一笔隐藏的交易可能光自己就有 40 TB 的自己,包含了 1 万亿个 SigOp,想想这有多麻烦(译者注:SigOp 可以理解为一种计量单位,每个与签名验证有关的指令都会用到一定量的 SigOp)。更糟糕的是,一些微型交易可能根本不使用 SigOp —— 也正因此,一个包含许多交易的 “熙熙攘攘的区块” 可能仍然是有效的。但也可能不是。谁知道呢!
简而言之,我们需要整个区块,然后我们才能恰当地处理它们!
真的需要吗?
B. 一个对整体有效的加项
也许,如果每个部分都唯一地声明了自己对整体的贡献,我们 就能 分析每个部分。只需要一种办法能度量一个 “贡献” 就行。
我来解释一下。
以区块体积的限制为例,我们将要求每笔交易声明自己在所 “生活” 的 “区块房产” 内的 “坐标”。我们不允许任何交易占据超出(或少于)它所声明的空间;也不允许任何两笔交易占据同一个声明空间。
所以,一笔交易不仅 “会占用 250 字节”;而且,我们还要做一些设计,让这笔交易 “占据 #32880 字节 到 #33130 字节之间的 250 字节”。
一个类比:想象一个区块内的交易全部要分别打印到一条纸带上,而且每一条纸带都是首尾相接来打印的,形成一个线段。我的提议是,我们首先把这条线段放到一个巨大的尺子上,其次我们给每条纸带增加两个 4 字节的空白片段11,然后让尺子给出每一条纸带的前后两个空白段的起始和结束坐标。
另外,在 “SPV+” 模式种,我家是 SPV 节点可以获得每个区块的第一笔交易和最后一笔交易。如果 “累加器” 从 0 开始,而每笔交易都为之增加了自己所声明的体积,那么累加器最终的值应该等于整个区块的总体积。如果不等,那就必然有一笔乃至多笔交易是有瑕疵的。这些交易因此犯了第一类错误,会触发 “无效交易保险”(见第 5 章)。
C. 累加器详述
我会从一个硬分叉累加器说起,因为它比较容易解释。
硬分叉
【回顾】在当前的比特币协议中,一笔交易 “x” 有哈希值 “h(x)”,而这些 h(x) 形成了区块的默克尔树的底层。
反过来,我们也许可以让每笔交易 “x” 都由 “y = h( h(x), h(z1, z2) )” 来表示,被放入哈希函数中的第二项就是一个 “累加器” —— 举个例子,z1 和 z2 将声明这笔交易中在区块中的起始和结束坐标。
(更具体地说,z1 和 z2 可以列出【许多信息】,因为这些信息需要描述,不仅包括该笔交易的体积,还包括它所用的 SigOp 数量、所支付的手续费,乃至 drivechain 的 Withdrawal_DB 的任何变更。)
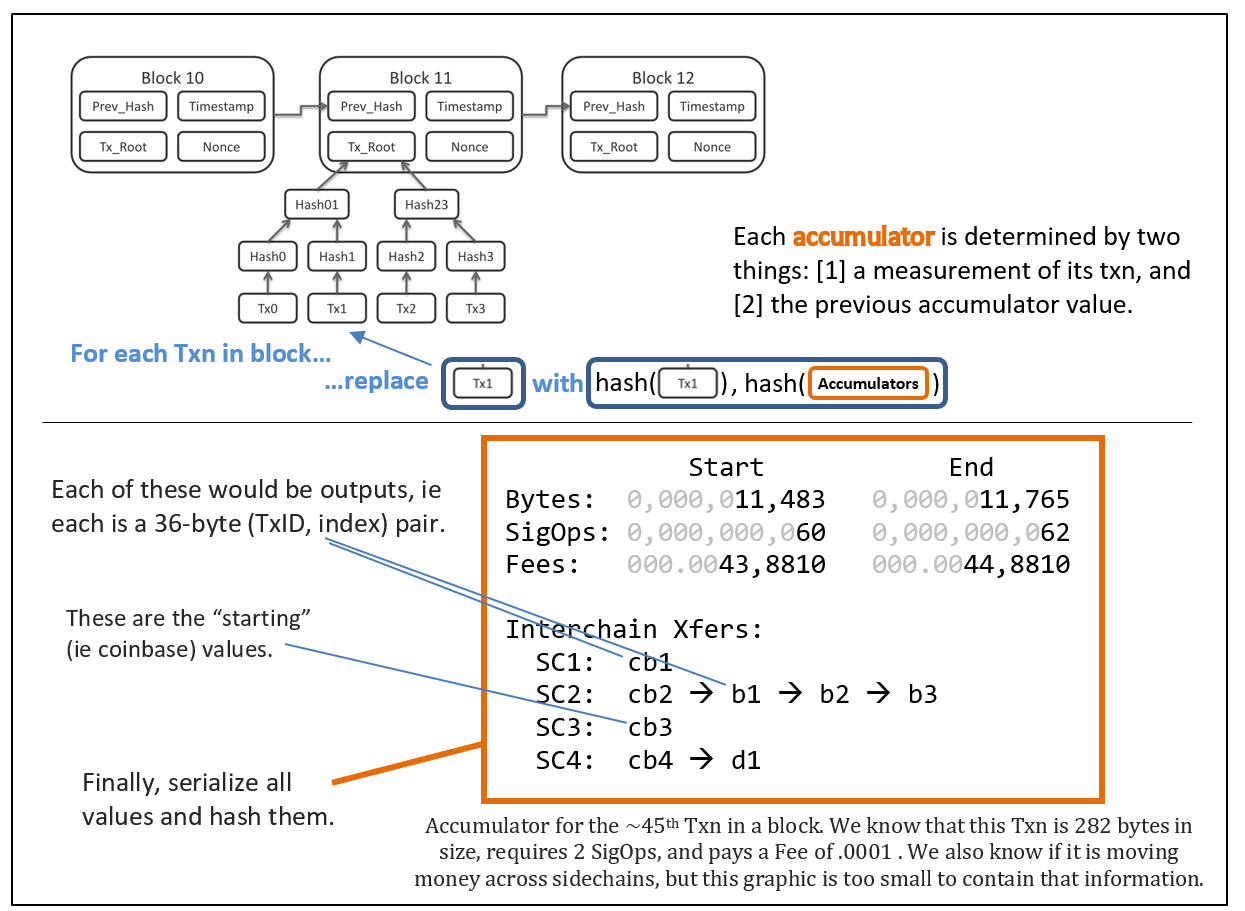
z1 和 z2 所提供的新信息并不需要实际广播到整个网络中,甚至不需要存储。只需在本地使用 x 的序列就可以生成出来以及验证它,就跟当前一样。【在区块被挖出之前】矿工依然可以完全随心所欲地安排交易在区块中的排序。
无论如何,这个数据结构(“累计的默克尔树”)会很有用,因为它使得证明欺诈变得非常容易。回想一下,我们需要同时提交 “不良交易” 以及证明其无效性的 “证据”。但当我们要描述一条通向该 “不良交易” 的路径时,我们已经有了 “y” 。所以现在,我们只需提供其原像 [h(x),z1,z2] 并忽略前 32 字节即可。
软分叉
软分叉的空间是非常大的。我也不确定 最适合 这种目的的软分叉是怎样的。需要更多研究!欢迎留下评论!
但一种办法是将 “(z1,z2)” 数据对理解为交易 “x” 的一个 “次级见证数据”。就像 SegWit 一样,我们可以构建另一棵默克尔树(这样说来就是比特币区块的第三棵了)来包含这些次级见证数据,要求它存在并要求 coinbase 交易中始终有对它的承诺。
这个方案的缺点在于,为了证明欺诈,你需要一个非常笨重的交易,以及三个默克尔分支。首先,像往常一样,你需要一个分支来这笔交易存在于这个区块中。
其次,你需要一个分支,是证明区块的 coinbase 交易的分支;最后,你需要(1)从 coinbase 交易中取出特定的一个输出;(2)扫描这个输出以确保这就是那个“次级见证输出”;(3)在此使用另一个默克尔分支,找出 “x” 的 “次级见证数据” 的哈希值。
而所有这些都要是一个通道脚本的一部分!那这个赎回脚本该有多大啊!我猜,这样一笔交易,如果广播上链,其体积可能是普通交易的至少 10 倍。我想想就直冒冷汗!但我认为 “笨拙的交易” 还从没使我们放弃过 ……
第二种技术是要求每笔交易都要跟一个没灵魂的 “僵尸交易” 配对 —— 这笔交易不移动任何资金,只是存在,使得我们可以在其中防止一个 OP Return 操作码,带上对次级见证数据的承诺。这个想法其实是非常糟糕的,因为它会为链上的每笔交易浪费约 80(?)字节的空间,而交易体积的中位数已经接近约 250 字节了。所以交易的体积都会增加约 30% !不可理喻 !我在这里提供这个想法只是为了帮助形成其它的软分叉思路。(注意,我们无法将承诺放在交易自身的一个 OP Return 输出中,因为用户无法容易获知他们的交易究竟在一个区块的哪个为之,除非跟矿工频繁接触,这就太烦人了。)
8. 经济学
A. 计算成本
首先,如我前面所说,Salliy 必须运行 “SPV+” 节点,预计每个区块要使用 2192 字节(而不是 80 字节)。
B. 市场出清价格
那么 “无效交易保险” 以及 “完整性保险” 可能要花多少钱呢?
I. 竞争
首要,这些保险服务可以由任何运行全节点的人提供。其次,根据定义,只要存在一个区块链网络,就意味着有许多互不信任的匿名参与者,每个都运行一个全节点。所以,“保险供应商” 可能会存在激烈的竞争,因此只能为服务收取边际成本附近的价格。
ii. 边际成本视察
那他们的边际成本是多少?为了提供这项服务,他们需要运行一个全节点,一个开放的支付通道,而且需要监控这个通道。幸运的是,许多人已经在运行全节点了,而且已经在监控自己的开放支付通道了,所以他们的边际成本几乎是零。只有通道有一些成本 —— 开启通道(或转移已有的一个)需要支付一小笔交易费,以及需要在通道中锁定一些资金。
但即使这些成本,也可以忽略不计。这些合约可以部署在已经开好的通道内,所以虽然开启一条新通道的成本不是零,为这个目的而开设通道的边际成本依然是零 —— 人们可以免费重用他们以及开启的通道。任何已经开设闪电网络连接的人,都不需要为了这个目的或其它目的而频繁开启或关闭。
注:通道便利性
因为我们正在讨论通道的 开启/关闭,需要指出,这种保险可以通过闪电网络来 “传播” —— 换句话来说,Sally 和 Fred 不需要具有直接相连的通道。他们只需要都处于同一个 “闪电网络” 中即可。所以 Sally 可以从 Fred 手上购买保险,然后卖给另一个 Sally!这将最大限度减少对通道 开启/关闭的需要。
细节较长,放在脚注中 12。
iii. 时间与资金
完整性审查
完整性审查只需持续很短的一段时间。所需的步骤可以很快完成:Sally 和 Fred 相遇、谈判条款、创建新的通道状态(转入动能状态)、Fred 作废、Sally 作废、Sally 揭晓自己的随机整数,Fred 揭晓与之相关的交易,然后他们一直迁移到一个新的(势能)通道状态。
因为它几乎没有边际成本,所以每次的完整性审查的价格是没有下限的。每次审查可以只花费百分之一美分,每个用户可以对每个区块做 40 次或者 50 次检查,因此每个区块要花费半美分。
我会将所有成本都换算为月度的费用。这会使得 “欺诈证明世界” 的成本与 “全节点世界” 的成本更容易比较。
假设每个月有 4383 个区块产生,每个区块作 50 次完整性审查,而每次检查花费百分之一美分,那么一个月的花销是 21.91 美元。
无效交易保险
不幸的是,无效交易保险需要持续更长时间,因为它需要反向证明。反向证明要花费的时间是一个安全参数;你可能会问:“如果一个区块中包含了一笔不良交易,要花多少时间来发现它呢?”
一个瑕疵一旦被发现,这个发现就会迅速传播。因为知情人会很快尝试 售卖 这个发现。
通过采用 无效交易保险/完整性审查 合约的逻辑并将其中一部分逆转,这种销售是很容易实现的。新的 “智能合约” 交易可能会是这种形式:“你现在给我支付 0.03 美元,而我,如果不能给你找出这个区块头所对应区块的瑕疵,我就还给你 1000 美元”13。因为 “印第安纳线人(Indiana the Informant)” 知道有这么一个瑕疵,就有动力向愿意买这个知识的人卖出这个知识。而且他有动力尽快卖出,因为这个 “独家知识” 一旦变得众所周知,价值就极速下降。
所以,这个安全参数需要随 第一个 诚实者发现一个瑕疵的时间而有所变化14。到底有多长呢?我们没法确定,但 12 小时的保险持续时间,应该是合理的。
那锁定 1 美元的资金 12 小时的成本是多少呢?这取决于市场利率。因为一个诚实的 Fred 知道这个项目是 “没有风险” 的,所以这个理论应该是【理论上,最低的】“无风险利率”,而因为查特比是一种通缩型的货币单位,这个利率不需要升水来补贴投资者【抵消通胀税】。所以,这个 “项目” 所需的【年化】利率可以非常低,2% 甚至 1% ,取决于当事人有没有别的可投资项目【具有这样的风险回报】。当前,没有 这样的风险回报,所以市场利率可以任意低,低到 0。
下面我将一些利率从以年为单位调整到以天、小时和十分钟为单位:
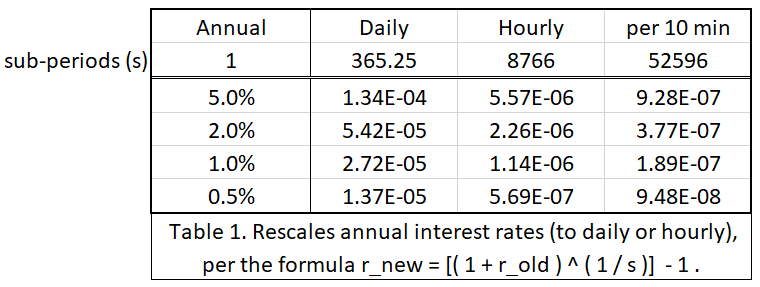
除了保险的 持续时间 意外,另一个安全参数是一个会 会买多少的保险。我会假设是价值 1000 美元的。当一个卖方愿意为几分钱押上自己的 1000 美金时,这本身就表明这个卖方真诚地相信这个区块有效的概率大于 99.99%。
最后,为便于解释,我将假设 Sally 总是为每一个区块头买保险。这可以帮助比较她和普通全节点用户(每个区块都检查)的偏执。
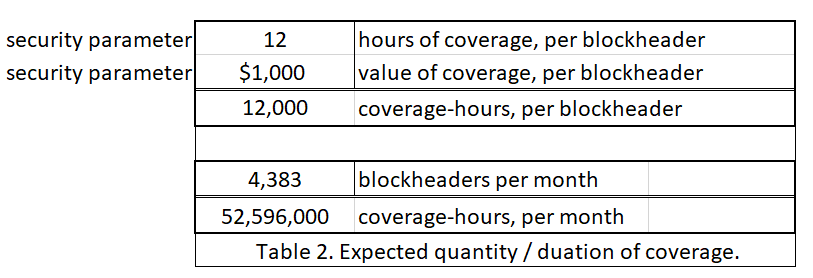
然后,我们可以看到购买无效交易保险,在不同利率下的月费。
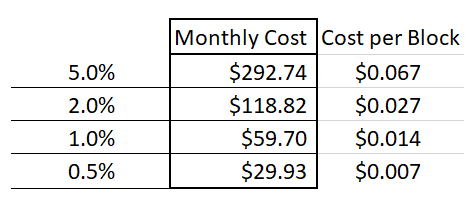
我们可以看到,每个月只需花费 29.93 美元即可。
总成本
因此,以 “被动” 方式验证每个区块的总成本月费大概在 51.84 美元。
这个价格受两个因素的影响:第一,是每个区块执行的完整性检查次数;第二,无效交易保险的安全参数选择(保险数量,保险持续期)。
可以合理地争议,这些因素都会随着网络变得更贵(即 “区块体积” 增大)而提高。不管怎么说,如果区块变得更大,有理由要成比例增加完整性审查的数量;而且,为无效交易保险提高 “保险持续期” 也是明智之举。
若是如此,它似乎跟使用欺诈证明的初衷相矛盾!
成本可扩展性
不过,我相信,相反的主张也有道理:51.84 美元的月费可能会一直保持,甚至有所降低。
举个例子,独立全节点的绝对数量的增加,必然意味着 在超规格硬件上运行 的节点的绝对数量增加。这些超级节点将更快检测到威胁 —— 通过上面说的过程来做,他们中的一些人应该会以此营利。
甚至,更多数量的 SPV 节点 也会使得 “专家验证者” 有利可图从而形成产业 —— 只需少数几个这样的专家就足以让整个社区得到全面保护(这可能是 “多眼假说(Many Eyes hypothesis)” 和 “群体免疫” 的案例)。
C. 部分完整性
Sally 没必要每个区块都验证完整性 —— 今天的几百万个 SPV 手机用户,活得好好的,根本不验证任何区块!
当然,一般来说,多作验证总比少作好,但 Sally 可能选择只验证少数区块。也许,在收到支付时,Sally 会验证包含了她的新交易的区块,以及在此之前的 400 个区块,以及在此之后的 20 个区块。又或者,Sally 仅仅随机抽取一些区块来验证。
9. 结论
欺诈证明解决了获知一个比特币区块头的有效性的问题(此前我们除了验证它具备有效的 PoW,别无他法)。这样的应用场景是非常罕见的。事实上,我认为,100% 的历史案例都是错误的(即都只是偶然),而且很快就被纠正了。
而且,这篇文章表述了许多想法,每一种光自己就是一个中等体量的项目。如果区块对普通人来说也很容易验证,那开发欺诈证明完全就是浪费时间。不过,如果区块很难验证,那欺诈证明就很有用武之地。
跟您说实话,我写这篇文章主要是想把这些东西从脑袋里丢出去!我快被它们逼疯了。
但现在,我冥想过了,感觉好多了,我希望你也喜欢。

- 落日,来自 Max Pixel -
脚注
1. “全节点” 与 “SPV 节点” 的区别也许并不像人们认为的那么清楚。简言之,当一个全节点在下载一个新区块时,相对于再下一个块,它自身是处于 SPV 模式中的。另外,再假设 51% 的算力在秘密运行一个新软件(或者说,是在运行一个新的但兼容的协议),该新软件默认增设区块延展数据(extension)。那么,即便别的节点想成为 “全节点”,也不得不变成部分全节点、部分 SPV 节点的混合模式。如果那些矿工后面又把协议改回去了,去除掉了延展数据要求,那么我们就又成为了 100% 的全节点。但是,在这个过程中可能你都没有意识到节点形态转变了,实际上你也没办法知道。所以,只有假设协议本身固定不变的情况下,使用这些数据才有意义,当然,本文也就是这么假设的。不过,实际上,协议可能变更,也确实会变更,矿工永远可以选择运行定制化的软件。↩
2. 准确点说,是对所有她想用 SPV 模式来 “完全验证” 的区块都要这么做(不想验证的就另算了)。↩
3. 对于自身是侧链的那些区块链,链间交易出错可以被归类为第一类错误。要得到错误警示,侧链的 SPV 节点需要找出两笔交易,一笔在主链上提供存款的交易,另一笔是在侧链上记录存入金额的交易。因此,侧链上的 Sally 必须检查主链和侧链两条链才能发现错误。↩
4. 单块的全部存储成本是:“区块头 + 第一笔交易 + 最后一笔交易 + 2 × (32 × log (2)(n))”,这里的 “log (2)(n) ” 指的是 “根据区块中交易的数量可得的空间占用上限”。因此,在本例中,单块的存储成本是 “80 + 1000 + 280 + 2 × (32 × log (2)(5000))”,大概是 2192 bytes。注意,我们不需要 coinbase 交易的位掩码,因为我们已经知道其确切结构(“它总是在最左边”),但我们可能需要知道最后一笔交易的(因为它可能在 “最右” 和 “self” 之间)。(这个数据应该会比把 self 编码为一个完全由 0 来组成的 branch-hash 要小,我已经在这里估计过了。)↩
5. 实际上,Sally 和 Fred 可以一次只使用一个随机数。这样的话,在最糟糕的情境下的脚本大小会小一些,但他们需要执行多次交互。↩
6. 这个故事是简化过的。实际上,Sally 不会公开那个整数,只会公开自己用于计算承诺的随机数。(“公开” 的解释见维基百科)↩
7. 实际上每一次配对交换都是完全定制化的,也可能加强隐私而定制化(举个例子)。但我这里只是要简介闪电网络,所以 “共享 H” 这个说法够用了。↩
8. 重申,在验证流程的这个环节,Sally 已经拥有整个区块头、也知道这个区块头满足难度要求了。TA 只需要评估哈希默克尔树根值就可以了。↩
9. 在实践中尤其值得关注的是交易验证规则改变了的情况(比如我们用软分叉增加了一个新的操作码)—— 此前有效(但没有被打包)的交易现在也可以变作无效。因此,如果某人指控某笔交易是无效的,我们需要知道交易发生的具体时间,以及该笔交易上链之时的共识规则,与当前的规则相对比。恐怖吧!但如果是一个静态的协议,也就是交易验证规则不会变化的协议,那就没什么问题了(如我在注 1 中解释的那样)。也许每次更改共识规则时都递增区块的版本号可以解决这个问题。又或者,Sally 升级自己的软件也可以 —— TA 可以继续使用 SPV 模式,但需要运行 最新的 SPV 模式以使用最新的规则。↩
10. 即,检查这个格式是可以理解的、输入的脚本是有效的,而且 sum(inputs) >= sum(outputs)(交易的输入资金数量大于等于输出资金数量),等等。每件事在普通的 “全节点” 验证中都会检查一遍。↩
11. 一个四字节的非负整数可以表示到 42.9 亿。所以足够描述沿着一个向量的一个点了,只要区块的体积没有超过 4.29 GB.而且,即时超过了,我们也可以使用模数(即,允许它溢出),因为从默克尔树的大小很容易看出区块是否小于 4.29 GB,小于 8.58 GB,等等。如我后面要解释的,这个数据并不需要实际广播到整个网络中,也不需要存储。它只是为了访问到正确的哈希默克尔根。↩
12. 这些中间节点扮演的角色类似于 “保险发起人” 或者 “再保险代理” 等中介 —— 保险发起人向终端客户销售保险,同时计划着立即将合约出售给 “真正的” 保险机构;而再保险代理向 “真正的” 保险机构销售保险,从而让合约(以及风险)脱手。 —— 对于无效交易保险,你以将满足脚本的 “证据” 交易看作一个更大、更复杂的 “R” 【回忆一下,R 是一个由买方选择的随机数,买方也计算出 h(R) = H 并基于同一个 H 构建一个支付 “环路”】。这个 “证据”,一旦在某处工勘,将触发给定的整个环路中的所有保险支付 —— 实际上,它会触发所有地方的 所有 环路【只要是针对同一无效区块头的】。—— 对于完整性审核,这个 “发起人” 将承担更多风险,相应低也可以收取更高的回报。这是因为发起人 (“Sally1”)要先升级一个真实的全节点(“Fred”),直到她们确信这个全节点真的是个全节点(换句话说,Sally1 审计 Fred 直到她相信对方是一个诚实的 Fred)。然后,Sally1 可以安全地向 Sally2 出售审计服务(举个例子)。Sally1 自己没法完成审计,因为按照定义,Sally2 会向她请求随机的交易,而 Sally1 并不保存任何交易。但 Sally 可以使用一次新的审核服务从 Fred 处获得这笔交易。—— 这些技术在当前的区块链规模下没有任何用处。但,理论上来说,如果区块变得难以验证,难得离谱(也许因为它们的体积上升到了 TB 级别),这些专业化的服务就将具有经济效率。当通道 开启/关闭 变得更贵,这些服务也会变得更有效率 —— 这可以从 “Sally2” 的例子中看出,如果 Sally2 可以直接跟 Fred 开启通道,就能避免一些麻烦。↩
13. 印第安纳现任可以如此销售第二类错误,就像销售第一类错误一样容易。他只需以高于市场利率的价格购买完整性审查。所有这些再保险商都会涌向他,而他可以从所有人处获得损害赔偿。然后,这些人也会反过来用同样的诡计欺骗那些还不知晓的人。所以关键信息(这个区块的某个部分丢失了)会迅速传播。↩
14. 注意,通过使用智能合约和自由市场交易,我们已经实现了劳动分工和相应的福利收益。↩